前面章節(jié)中我們已經(jīng)學(xué)會了如何用 Python 輸出 "Hello, World!",英文沒有問題,但是如果你輸出中文字符 "你好,世界" 就有可能會碰到中文編碼問題。
Python 文件中如果未指定編碼,在執(zhí)行過程會出現(xiàn)報錯:
#!/usr/bin/python
print ("你好,世界")
以上程序執(zhí)行輸出結(jié)果為:
File "test.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file test.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Python中默認的編碼格式是 ASCII 格式,在沒修改編碼格式時無法正確打印漢字,所以在讀取中文時會報錯。
解決方法為只要在文件開頭加入 # -*- coding: UTF-8 -*- 或者 # coding=utf-8 就行了
注意:# coding=utf-8 的 = 號兩邊不要空格。
實例(Python 2.0+)
#!/usr/bin/python # -*- coding: UTF-8 -*- print( "你好,世界" )運行實例 »
輸出結(jié)果為:
你好,世界
所以如果大家在學(xué)習(xí)過程中,代碼中包含中文,就需要在頭部指定編碼。
注意:Python3.X 源碼文件默認使用utf-8編碼,所以可以正常解析中文,無需指定 UTF-8 編碼。
注意:如果你使用編輯器,同時需要設(shè)置 py 文件存儲的格式為 UTF-8,否則會出現(xiàn)類似以下錯誤信息:
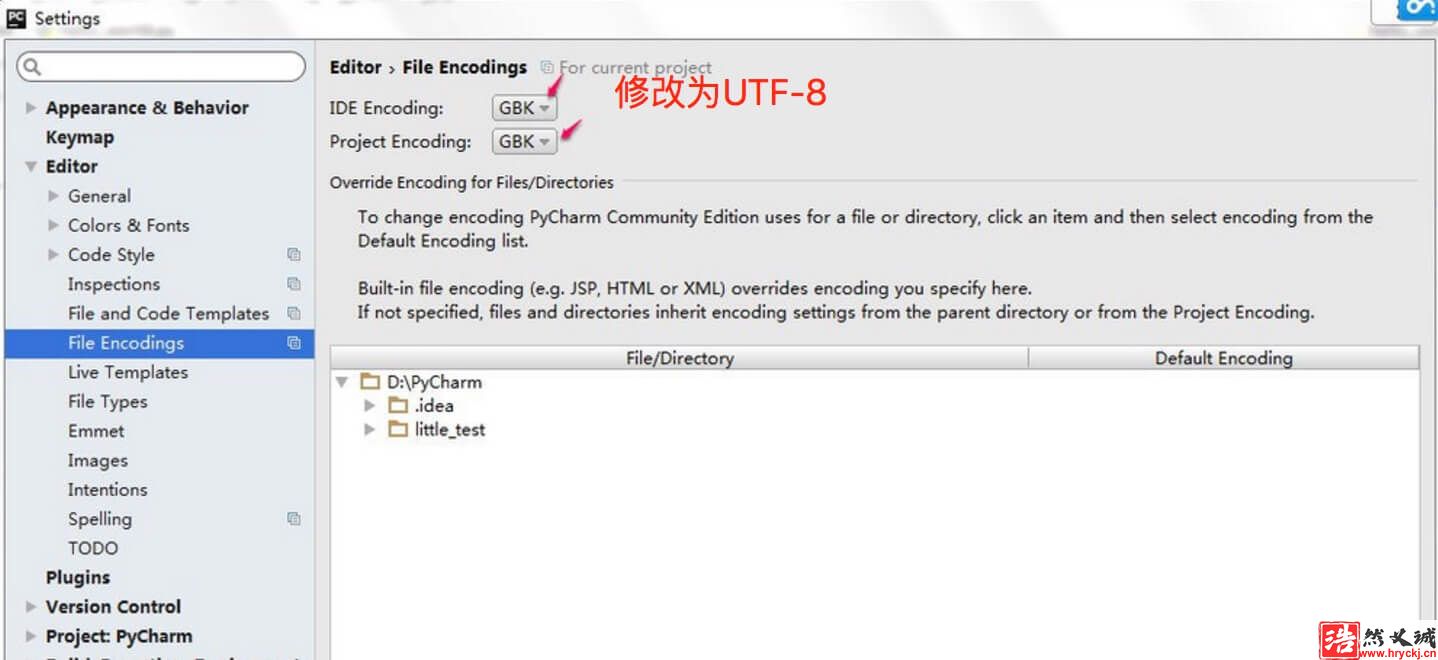
SyntaxError: (unicode error) ‘utf-8’ codec can’t decode byte 0xc4 in position 0: invalid continuation bytePycharm 設(shè)置步驟:
- 進入 file > Settings,在輸入框搜索 encoding。
- 找到 Editor > File encodings,將 IDE Encoding 和 Project Encoding 設(shè)置為utf-8。